Nine Rules About Deepseek Meant To Be Damaged
페이지 정보
작성자 Christi 작성일25-01-31 08:54 조회261회 댓글0건관련링크
본문
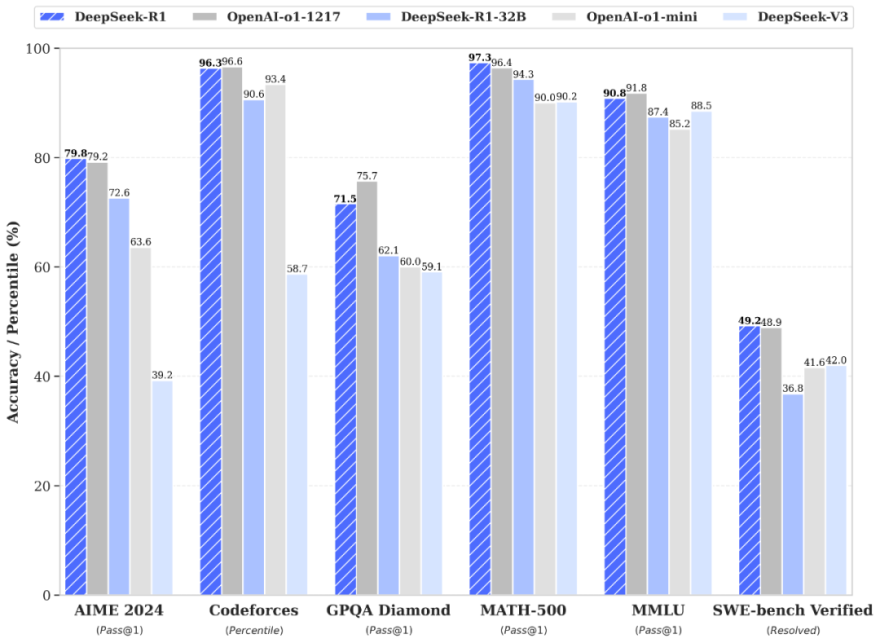 DeepSeek V3 also crushes the competition on Aider Polyglot, a test designed to measure, amongst different things, whether a model can successfully write new code that integrates into existing code. The political attitudes take a look at reveals two types of responses from Qianwen and Baichuan. Comparing their technical reviews, DeepSeek seems essentially the most gung-ho about safety coaching: along with gathering security data that embody "various delicate matters," DeepSeek also established a twenty-individual group to construct test cases for a variety of safety categories, whereas being attentive to altering methods of inquiry so that the fashions wouldn't be "tricked" into providing unsafe responses. While the wealthy can afford to pay greater premiums, that doesn’t mean they’re entitled to higher healthcare than others. While the Chinese authorities maintains that the PRC implements the socialist "rule of regulation," Western students have commonly criticized the PRC as a rustic with "rule by law" as a result of lack of judiciary independence. When we requested the Baichuan web mannequin the same question in English, nonetheless, it gave us a response that both properly explained the difference between the "rule of law" and "rule by law" and asserted that China is a rustic with rule by legislation.
DeepSeek V3 also crushes the competition on Aider Polyglot, a test designed to measure, amongst different things, whether a model can successfully write new code that integrates into existing code. The political attitudes take a look at reveals two types of responses from Qianwen and Baichuan. Comparing their technical reviews, DeepSeek seems essentially the most gung-ho about safety coaching: along with gathering security data that embody "various delicate matters," DeepSeek also established a twenty-individual group to construct test cases for a variety of safety categories, whereas being attentive to altering methods of inquiry so that the fashions wouldn't be "tricked" into providing unsafe responses. While the wealthy can afford to pay greater premiums, that doesn’t mean they’re entitled to higher healthcare than others. While the Chinese authorities maintains that the PRC implements the socialist "rule of regulation," Western students have commonly criticized the PRC as a rustic with "rule by law" as a result of lack of judiciary independence. When we requested the Baichuan web mannequin the same question in English, nonetheless, it gave us a response that both properly explained the difference between the "rule of law" and "rule by law" and asserted that China is a rustic with rule by legislation.
 The question on the rule of regulation generated the most divided responses - showcasing how diverging narratives in China and the West can influence LLM outputs. We’ll get into the precise numbers beneath, but the query is, which of the various technical innovations listed in the DeepSeek V3 report contributed most to its learning effectivity - i.e. mannequin efficiency relative to compute used. Together, we’ll chart a course for prosperity and fairness, ensuring that each citizen feels the benefits of a renewed partnership built on belief and dignity. These benefits can lead to higher outcomes for patients who can afford to pay for them. So simply because an individual is keen to pay higher premiums, doesn’t imply they deserve higher care. The only exhausting limit is me - I must ‘want’ something and be prepared to be curious in seeing how a lot the AI can help me in doing that. Today, everybody on the planet with an internet connection can freely converse with an extremely knowledgable, patient trainer who will help them in anything they will articulate and - where the ask is digital - will even produce the code to assist them do even more sophisticated things.
The question on the rule of regulation generated the most divided responses - showcasing how diverging narratives in China and the West can influence LLM outputs. We’ll get into the precise numbers beneath, but the query is, which of the various technical innovations listed in the DeepSeek V3 report contributed most to its learning effectivity - i.e. mannequin efficiency relative to compute used. Together, we’ll chart a course for prosperity and fairness, ensuring that each citizen feels the benefits of a renewed partnership built on belief and dignity. These benefits can lead to higher outcomes for patients who can afford to pay for them. So simply because an individual is keen to pay higher premiums, doesn’t imply they deserve higher care. The only exhausting limit is me - I must ‘want’ something and be prepared to be curious in seeing how a lot the AI can help me in doing that. Today, everybody on the planet with an internet connection can freely converse with an extremely knowledgable, patient trainer who will help them in anything they will articulate and - where the ask is digital - will even produce the code to assist them do even more sophisticated things.
Today, we draw a transparent line in the digital sand - any infringement on our cybersecurity will meet swift consequences. Today, we put America again at the middle of the global stage. America! On this historic day, we gather as soon as again under the banner of freedom, unity, and strength - and together, we begin anew. America First, remember that phrase? Give it a try! As essentially the most censored model among the many models examined, DeepSeek’s net interface tended to give shorter responses which echo Beijing’s speaking factors. U.S. capital might thus be inadvertently fueling Beijing’s indigenization drive. This means that despite the provisions of the law, its implementation and software may be affected by political and economic components, as well as the personal interests of these in power. The tremendous-tuning job relied on a uncommon dataset he’d painstakingly gathered over months - a compilation of interviews psychiatrists had performed with patients with psychosis, in addition to interviews those self same psychiatrists had completed with AI methods. Step 1: Initially pre-trained with a dataset consisting of 87% code, 10% code-associated language (Github Markdown and StackExchange), and 3% non-code-associated Chinese language.
DeepSeek LLM is an advanced language mannequin accessible in both 7 billion and 67 billion parameters. The whole compute used for the DeepSeek V3 model for pretraining experiments would possible be 2-4 instances the reported number within the paper. This is probably going DeepSeek’s best pretraining cluster and they've many other GPUs which are either not geographically co-situated or lack chip-ban-restricted communication gear making the throughput of other GPUs decrease. On the TruthfulQA benchmark, InstructGPT generates truthful and informative answers about twice as often as GPT-three During RLHF fine-tuning, we observe performance regressions in comparison with GPT-3 We can significantly cut back the efficiency regressions on these datasets by mixing PPO updates with updates that improve the log probability of the pretraining distribution (PPO-ptx), with out compromising labeler desire scores. Like Qianwen, Baichuan’s solutions on its official web site and Hugging Face occasionally different. Its total messaging conformed to the Party-state’s official narrative - but it surely generated phrases similar to "the rule of Frosty" and mixed in Chinese phrases in its answer (above, 番茄贸易, ie. BIOPROT accommodates 100 protocols with an average number of 12.5 steps per protocol, with each protocol consisting of around 641 tokens (very roughly, 400-500 words).
댓글목록
등록된 댓글이 없습니다.