Best Deepseek Tips You'll Read This Year
페이지 정보
작성자 Gus 작성일25-02-01 00:31 조회6회 댓글0건관련링크
본문
 DeepSeek mentioned it could launch R1 as open source however did not announce licensing terms or a launch date. Within the face of disruptive applied sciences, moats created by closed source are temporary. Even OpenAI’s closed supply strategy can’t forestall others from catching up. One factor to take into consideration as the strategy to building high quality coaching to show folks Chapel is that in the mean time the best code generator for various programming languages is Deepseek Coder 2.1 which is freely available to make use of by people. Why this matters - textual content video games are onerous to be taught and will require rich conceptual representations: Go and play a text journey recreation and notice your own expertise - you’re each learning the gameworld and ruleset whereas additionally constructing a wealthy cognitive map of the surroundings implied by the textual content and the visual representations. What analogies are getting at what deeply matters versus what analogies are superficial? A 12 months that started with OpenAI dominance is now ending with Anthropic’s Claude being my used LLM and the introduction of a number of labs which might be all making an attempt to push the frontier from xAI to Chinese labs like DeepSeek and Qwen.
DeepSeek mentioned it could launch R1 as open source however did not announce licensing terms or a launch date. Within the face of disruptive applied sciences, moats created by closed source are temporary. Even OpenAI’s closed supply strategy can’t forestall others from catching up. One factor to take into consideration as the strategy to building high quality coaching to show folks Chapel is that in the mean time the best code generator for various programming languages is Deepseek Coder 2.1 which is freely available to make use of by people. Why this matters - textual content video games are onerous to be taught and will require rich conceptual representations: Go and play a text journey recreation and notice your own expertise - you’re each learning the gameworld and ruleset whereas additionally constructing a wealthy cognitive map of the surroundings implied by the textual content and the visual representations. What analogies are getting at what deeply matters versus what analogies are superficial? A 12 months that started with OpenAI dominance is now ending with Anthropic’s Claude being my used LLM and the introduction of a number of labs which might be all making an attempt to push the frontier from xAI to Chinese labs like DeepSeek and Qwen.
 free deepseek v3 benchmarks comparably to Claude 3.5 Sonnet, indicating that it's now potential to practice a frontier-class mannequin (not less than for the 2024 model of the frontier) for less than $6 million! In response to Clem Delangue, the CEO of Hugging Face, one of many platforms hosting DeepSeek’s fashions, developers on Hugging Face have created over 500 "derivative" fashions of R1 which have racked up 2.5 million downloads combined. The mannequin, deepseek ai V3, was developed by the AI agency DeepSeek and was launched on Wednesday beneath a permissive license that allows developers to download and modify it for many functions, together with commercial ones. Listen to this story an organization based in China which goals to "unravel the mystery of AGI with curiosity has launched DeepSeek LLM, a 67 billion parameter mannequin educated meticulously from scratch on a dataset consisting of 2 trillion tokens. DeepSeek, a company based in China which goals to "unravel the mystery of AGI with curiosity," has launched DeepSeek LLM, a 67 billion parameter mannequin trained meticulously from scratch on a dataset consisting of 2 trillion tokens. Recently, Alibaba, the chinese tech giant also unveiled its own LLM referred to as Qwen-72B, which has been skilled on high-high quality information consisting of 3T tokens and also an expanded context window length of 32K. Not simply that, the company additionally added a smaller language model, Qwen-1.8B, touting it as a reward to the analysis group.
free deepseek v3 benchmarks comparably to Claude 3.5 Sonnet, indicating that it's now potential to practice a frontier-class mannequin (not less than for the 2024 model of the frontier) for less than $6 million! In response to Clem Delangue, the CEO of Hugging Face, one of many platforms hosting DeepSeek’s fashions, developers on Hugging Face have created over 500 "derivative" fashions of R1 which have racked up 2.5 million downloads combined. The mannequin, deepseek ai V3, was developed by the AI agency DeepSeek and was launched on Wednesday beneath a permissive license that allows developers to download and modify it for many functions, together with commercial ones. Listen to this story an organization based in China which goals to "unravel the mystery of AGI with curiosity has launched DeepSeek LLM, a 67 billion parameter mannequin educated meticulously from scratch on a dataset consisting of 2 trillion tokens. DeepSeek, a company based in China which goals to "unravel the mystery of AGI with curiosity," has launched DeepSeek LLM, a 67 billion parameter mannequin trained meticulously from scratch on a dataset consisting of 2 trillion tokens. Recently, Alibaba, the chinese tech giant also unveiled its own LLM referred to as Qwen-72B, which has been skilled on high-high quality information consisting of 3T tokens and also an expanded context window length of 32K. Not simply that, the company additionally added a smaller language model, Qwen-1.8B, touting it as a reward to the analysis group.
I believe succeeding at Nethack is incredibly onerous and requires a very good long-horizon context system as well as an potential to infer fairly advanced relationships in an undocumented world. This yr we have seen significant improvements on the frontier in capabilities as well as a brand new scaling paradigm. While RoPE has labored effectively empirically and gave us a method to increase context windows, I think something extra architecturally coded feels higher asthetically. A more speculative prediction is that we will see a RoPE replacement or at the very least a variant. Second, when DeepSeek developed MLA, they wanted to add other things (for eg having a weird concatenation of positional encodings and no positional encodings) beyond simply projecting the keys and values due to RoPE. Being able to ⌥-Space right into a ChatGPT session is tremendous handy. Depending on how a lot VRAM you've in your machine, you might be able to make the most of Ollama’s potential to run a number of models and handle multiple concurrent requests through the use of DeepSeek Coder 6.7B for autocomplete and Llama 3 8B for chat. All this may run fully by yourself laptop computer or have Ollama deployed on a server to remotely energy code completion and chat experiences based in your wants.
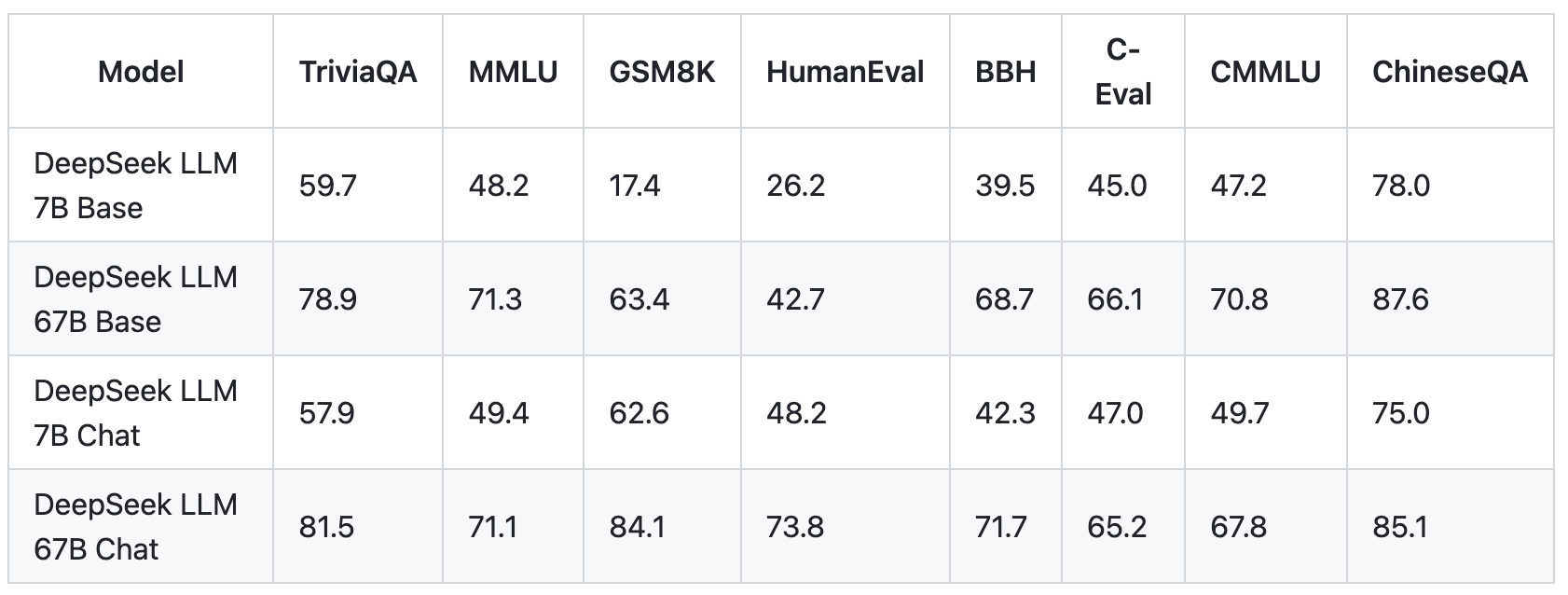
"This run presents a loss curve and convergence fee that meets or exceeds centralized training," Nous writes. The pre-training process, with specific particulars on coaching loss curves and benchmark metrics, is released to the general public, emphasising transparency and accessibility. DeepSeek LLM 7B/67B models, including base and chat variations, are released to the public on GitHub, Hugging Face and in addition AWS S3. The research community is granted entry to the open-source variations, DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat. And so when the model requested he give it access to the internet so it may perform more research into the character of self and psychosis and ego, he mentioned yes. The benchmarks largely say sure. In-depth evaluations have been performed on the base and chat fashions, comparing them to existing benchmarks. The past 2 years have additionally been nice for research. However, with 22B parameters and a non-production license, it requires quite a bit of VRAM and can only be used for analysis and testing purposes, so it might not be one of the best fit for daily local usage. Large Language Models are undoubtedly the biggest part of the current AI wave and is currently the area the place most analysis and funding goes towards.
If you have any kind of queries regarding exactly where and also tips on how to make use of ديب سيك, you can e-mail us with our web site.
댓글목록
등록된 댓글이 없습니다.