Unknown Facts About Deepseek Revealed By The Experts
페이지 정보
작성자 Barry 작성일25-02-01 09:02 조회4회 댓글0건관련링크
본문
 DeepSeek-V2 is a large-scale mannequin and competes with different frontier programs like LLaMA 3, Mixtral, DBRX, and Chinese models like Qwen-1.5 and DeepSeek V1. So I believe you’ll see more of that this yr as a result of LLaMA three goes to come back out sooner or later. Versus in the event you look at Mistral, the Mistral group got here out of Meta and they were a number of the authors on the LLaMA paper. Jordan Schneider: Well, what is the rationale for a Mistral or a Meta to spend, I don’t know, 100 billion dollars coaching something after which simply put it out for free deepseek? You may even have individuals dwelling at OpenAI that have distinctive ideas, however don’t actually have the remainder of the stack to help them put it into use. You want people which might be algorithm experts, however then you additionally need people which are system engineering consultants. It excels in areas which can be traditionally challenging for AI, like superior arithmetic and code generation. It’s virtually like the winners carry on profitable. You'll be able to obviously copy loads of the end product, but it’s laborious to copy the method that takes you to it. Released below Apache 2.Zero license, it may be deployed regionally or on cloud platforms, and its chat-tuned model competes with 13B fashions.
DeepSeek-V2 is a large-scale mannequin and competes with different frontier programs like LLaMA 3, Mixtral, DBRX, and Chinese models like Qwen-1.5 and DeepSeek V1. So I believe you’ll see more of that this yr as a result of LLaMA three goes to come back out sooner or later. Versus in the event you look at Mistral, the Mistral group got here out of Meta and they were a number of the authors on the LLaMA paper. Jordan Schneider: Well, what is the rationale for a Mistral or a Meta to spend, I don’t know, 100 billion dollars coaching something after which simply put it out for free deepseek? You may even have individuals dwelling at OpenAI that have distinctive ideas, however don’t actually have the remainder of the stack to help them put it into use. You want people which might be algorithm experts, however then you additionally need people which are system engineering consultants. It excels in areas which can be traditionally challenging for AI, like superior arithmetic and code generation. It’s virtually like the winners carry on profitable. You'll be able to obviously copy loads of the end product, but it’s laborious to copy the method that takes you to it. Released below Apache 2.Zero license, it may be deployed regionally or on cloud platforms, and its chat-tuned model competes with 13B fashions.
 I think open source goes to go in an identical means, the place open source goes to be nice at doing fashions in the 7, 15, 70-billion-parameters-vary; and they’re going to be nice models. Alessio Fanelli: I used to be going to say, Jordan, one other strategy to think about it, just in terms of open supply and not as comparable yet to the AI world where some nations, and even China in a method, have been perhaps our place is not to be at the innovative of this. China as soon as again demonstrates that resourcefulness can overcome limitations. Despite its reputation with international customers, the app appears to censor answers to sensitive questions about China and its government. Despite the efficiency advantage of the FP8 format, sure operators still require a higher precision on account of their sensitivity to low-precision computations. The DeepSeek workforce carried out intensive low-degree engineering to realize efficiency. We first rent a staff of 40 contractors to label our data, based mostly on their performance on a screening tes We then acquire a dataset of human-written demonstrations of the specified output behavior on (largely English) prompts submitted to the OpenAI API3 and some labeler-written prompts, and use this to train our supervised studying baselines.
I think open source goes to go in an identical means, the place open source goes to be nice at doing fashions in the 7, 15, 70-billion-parameters-vary; and they’re going to be nice models. Alessio Fanelli: I used to be going to say, Jordan, one other strategy to think about it, just in terms of open supply and not as comparable yet to the AI world where some nations, and even China in a method, have been perhaps our place is not to be at the innovative of this. China as soon as again demonstrates that resourcefulness can overcome limitations. Despite its reputation with international customers, the app appears to censor answers to sensitive questions about China and its government. Despite the efficiency advantage of the FP8 format, sure operators still require a higher precision on account of their sensitivity to low-precision computations. The DeepSeek workforce carried out intensive low-degree engineering to realize efficiency. We first rent a staff of 40 contractors to label our data, based mostly on their performance on a screening tes We then acquire a dataset of human-written demonstrations of the specified output behavior on (largely English) prompts submitted to the OpenAI API3 and some labeler-written prompts, and use this to train our supervised studying baselines.
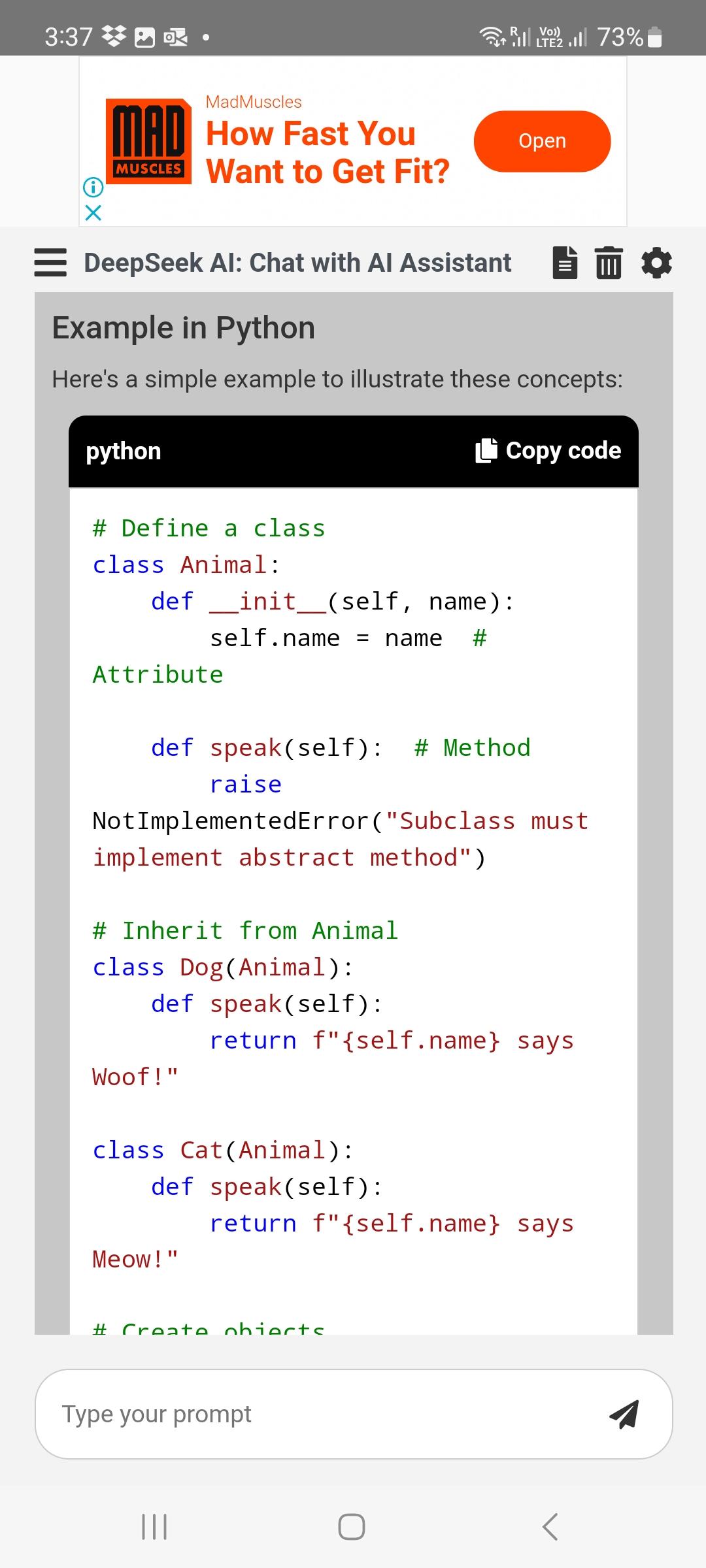
These distilled models do well, approaching the efficiency of OpenAI’s o1-mini on CodeForces (Qwen-32b and Llama-70b) and outperforming it on MATH-500. Say a state actor hacks the GPT-4 weights and will get to learn all of OpenAI’s emails for just a few months. Mistral solely put out their 7B and 8x7B models, but their Mistral Medium mannequin is effectively closed supply, similar to OpenAI’s. That Microsoft effectively constructed an entire data middle, out in Austin, for OpenAI. This code creates a basic Trie information construction and supplies methods to insert phrases, search for phrases, and check if a prefix is present in the Trie. Today, everybody on the planet with an web connection can freely converse with an extremely knowledgable, patient teacher who will assist them in something they'll articulate and - where the ask is digital - will even produce the code to assist them do even more difficult issues. Its 128K token context window means it may possibly course of and understand very lengthy documents. The researchers used an iterative process to generate synthetic proof data. To hurry up the process, the researchers proved each the unique statements and their negations.
It really works in theory: In a simulated check, the researchers construct a cluster for AI inference testing out how well these hypothesized lite-GPUs would carry out against H100s. So you’re already two years behind once you’ve figured out the way to run it, which isn't even that easy. So if you think about mixture of specialists, if you happen to look at the Mistral MoE mannequin, which is 8x7 billion parameters, heads, you need about eighty gigabytes of VRAM to run it, which is the most important H100 on the market. A number of the trick with AI is determining the precise technique to prepare these things so that you've got a activity which is doable (e.g, taking part in soccer) which is on the goldilocks stage of difficulty - sufficiently difficult it's good to come up with some good things to succeed at all, but sufficiently easy that it’s not impossible to make progress from a cold start.
댓글목록
등록된 댓글이 없습니다.