7 Information Everyone Ought to Find out about Deepseek
페이지 정보
작성자 Johnie Pacheco 작성일25-02-01 17:41 조회10회 댓글0건관련링크
본문
So far, the CAC has greenlighted models similar to Baichuan and Qianwen, which shouldn't have safety protocols as complete as DeepSeek. The essential question is whether or not the CCP will persist in compromising safety for progress, particularly if the progress of Chinese LLM technologies begins to succeed in its restrict. Even so, LLM improvement is a nascent and quickly evolving field - in the long run, it's uncertain whether or not Chinese developers will have the hardware capacity and talent pool to surpass their US counterparts. While GPT-4-Turbo can have as many as 1T params. While our present work focuses on distilling information from mathematics and coding domains, this approach exhibits potential for broader functions across various process domains. The upside is that they tend to be more reliable in domains corresponding to physics, science, and math. On the one hand, updating CRA, for the React group, would mean supporting extra than simply a standard webpack "front-end only" react scaffold, since they're now neck-deep seek in pushing Server Components down everyone's gullet (I'm opinionated about this and towards it as you would possibly inform).
 If the export controls find yourself enjoying out the best way that the Biden administration hopes they do, then you could channel a complete country and multiple monumental billion-greenback startups and firms into going down these growth paths. The cost of decentralization: An vital caveat to all of this is none of this comes at no cost - coaching fashions in a distributed approach comes with hits to the efficiency with which you gentle up every GPU during training. Combined with 119K GPU hours for the context length extension and 5K GPU hours for submit-training, DeepSeek-V3 costs solely 2.788M GPU hours for its full training. For engineering-related tasks, while DeepSeek-V3 performs barely under Claude-Sonnet-3.5, it still outpaces all different models by a big margin, demonstrating its competitiveness across various technical benchmarks. The open-supply world, to date, has more been in regards to the "GPU poors." So if you happen to don’t have plenty of GPUs, but you continue to need to get enterprise worth from AI, how are you able to do that?
If the export controls find yourself enjoying out the best way that the Biden administration hopes they do, then you could channel a complete country and multiple monumental billion-greenback startups and firms into going down these growth paths. The cost of decentralization: An vital caveat to all of this is none of this comes at no cost - coaching fashions in a distributed approach comes with hits to the efficiency with which you gentle up every GPU during training. Combined with 119K GPU hours for the context length extension and 5K GPU hours for submit-training, DeepSeek-V3 costs solely 2.788M GPU hours for its full training. For engineering-related tasks, while DeepSeek-V3 performs barely under Claude-Sonnet-3.5, it still outpaces all different models by a big margin, demonstrating its competitiveness across various technical benchmarks. The open-supply world, to date, has more been in regards to the "GPU poors." So if you happen to don’t have plenty of GPUs, but you continue to need to get enterprise worth from AI, how are you able to do that?
"At the core of AutoRT is an massive foundation mannequin that acts as a robot orchestrator, prescribing applicable tasks to one or more robots in an environment based mostly on the user’s prompt and environmental affordances ("task proposals") discovered from visual observations. When comparing mannequin outputs on Hugging Face with those on platforms oriented in direction of the Chinese viewers, models subject to less stringent censorship offered more substantive answers to politically nuanced inquiries. This is another instance that means English responses are much less likely to set off censorship-driven solutions. The findings of this examine counsel that, by a mix of targeted alignment training and keyword filtering, it is feasible to tailor the responses of LLM chatbots to mirror the values endorsed by Beijing. Hybrid 8-bit floating level (HFP8) coaching and inference for deep seek neural networks. Efficient coaching of giant fashions calls for excessive-bandwidth communication, low latency, and speedy knowledge transfer between chips for both ahead passes (propagating activations) and backward passes (gradient descent). The unhappy factor is as time passes we know less and less about what the big labs are doing as a result of they don’t tell us, at all. We even requested. The machines didn’t know. The output high quality of Qianwen and Baichuan also approached ChatGPT4 for questions that didn’t touch on delicate topics - especially for their responses in English.
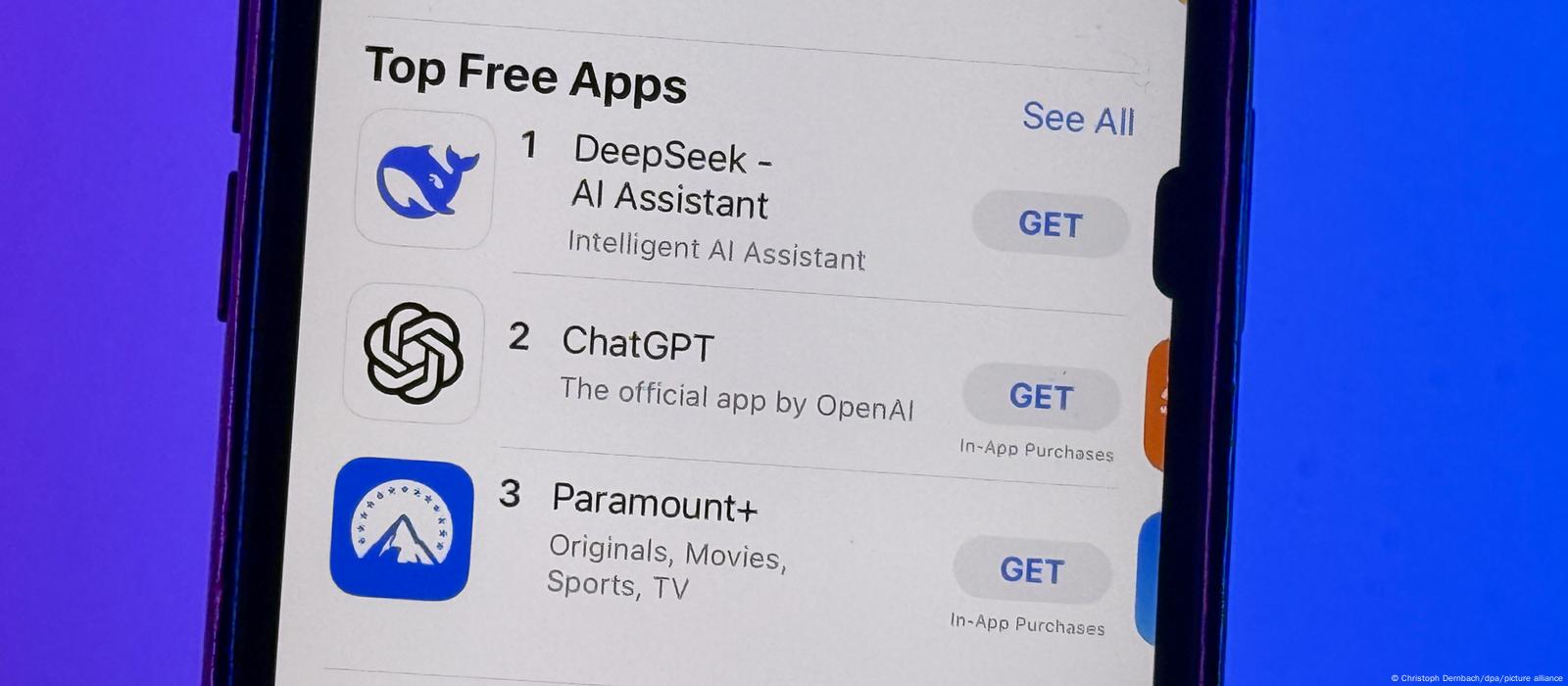 Even so, keyword filters restricted their means to reply delicate questions. This innovation raises profound questions about the boundaries of artificial intelligence and its lengthy-time period implications. It’s one model that does every thing rather well and it’s amazing and all these different things, and will get closer and nearer to human intelligence. DeepSeek persistently adheres to the route of open-source models with longtermism, aiming to steadily strategy the ultimate objective of AGI (Artificial General Intelligence). What are the psychological fashions or frameworks you employ to assume about the hole between what’s obtainable in open supply plus advantageous-tuning as opposed to what the main labs produce? Say all I wish to do is take what’s open supply and possibly tweak it a bit of bit for my particular firm, or use case, or language, or what have you. Typically, what you would need is some understanding of the right way to tremendous-tune these open supply-fashions. Plenty of times, it’s cheaper to unravel these problems since you don’t want a variety of GPUs.
Even so, keyword filters restricted their means to reply delicate questions. This innovation raises profound questions about the boundaries of artificial intelligence and its lengthy-time period implications. It’s one model that does every thing rather well and it’s amazing and all these different things, and will get closer and nearer to human intelligence. DeepSeek persistently adheres to the route of open-source models with longtermism, aiming to steadily strategy the ultimate objective of AGI (Artificial General Intelligence). What are the psychological fashions or frameworks you employ to assume about the hole between what’s obtainable in open supply plus advantageous-tuning as opposed to what the main labs produce? Say all I wish to do is take what’s open supply and possibly tweak it a bit of bit for my particular firm, or use case, or language, or what have you. Typically, what you would need is some understanding of the right way to tremendous-tune these open supply-fashions. Plenty of times, it’s cheaper to unravel these problems since you don’t want a variety of GPUs.
댓글목록
등록된 댓글이 없습니다.