7 Ways To Master Deepseek Without Breaking A Sweat
페이지 정보
작성자 Darwin Lundy 작성일25-02-09 16:44 조회12회 댓글0건관련링크
본문
 OpenAI lately accused DeepSeek of inappropriately utilizing data pulled from considered one of its models to practice DeepSeek. AWS is a close accomplice of OIT and Notre Dame, and they ensure information privateness of all the models run by Bedrock. This action highlights the importance of transparent information practices and compliance with international privateness standards to earn person trust and facilitate world adoption. To achieve broader market acceptance, DeepSeek should navigate complex international rules and construct belief throughout diverse markets. The effectiveness demonstrated in these particular areas indicates that lengthy-CoT distillation may very well be priceless for enhancing mannequin efficiency in different cognitive tasks requiring advanced reasoning. The most well-liked, DeepSeek-Coder-V2, stays at the highest in coding duties and can be run with Ollama, making it notably enticing for indie developers and coders. Deepseek is a standout addition to the AI world, combining superior language processing with specialized coding capabilities. In the Thirty-eighth Annual Conference on Neural Information Processing Systems. A high-tech illustration of AI inference pace and efficiency, highlighting real-time information processing and optimization. To maximise effectivity, the coaching course of integrated specialized load-balancing methods, ensuring that all consultants had been utilized successfully with out redundancy. Also setting it other than different AI instruments, the DeepThink (R1) model exhibits you its actual "thought course of" and the time it took to get the answer earlier than providing you with a detailed reply.
OpenAI lately accused DeepSeek of inappropriately utilizing data pulled from considered one of its models to practice DeepSeek. AWS is a close accomplice of OIT and Notre Dame, and they ensure information privateness of all the models run by Bedrock. This action highlights the importance of transparent information practices and compliance with international privateness standards to earn person trust and facilitate world adoption. To achieve broader market acceptance, DeepSeek should navigate complex international rules and construct belief throughout diverse markets. The effectiveness demonstrated in these particular areas indicates that lengthy-CoT distillation may very well be priceless for enhancing mannequin efficiency in different cognitive tasks requiring advanced reasoning. The most well-liked, DeepSeek-Coder-V2, stays at the highest in coding duties and can be run with Ollama, making it notably enticing for indie developers and coders. Deepseek is a standout addition to the AI world, combining superior language processing with specialized coding capabilities. In the Thirty-eighth Annual Conference on Neural Information Processing Systems. A high-tech illustration of AI inference pace and efficiency, highlighting real-time information processing and optimization. To maximise effectivity, the coaching course of integrated specialized load-balancing methods, ensuring that all consultants had been utilized successfully with out redundancy. Also setting it other than different AI instruments, the DeepThink (R1) model exhibits you its actual "thought course of" and the time it took to get the answer earlier than providing you with a detailed reply.
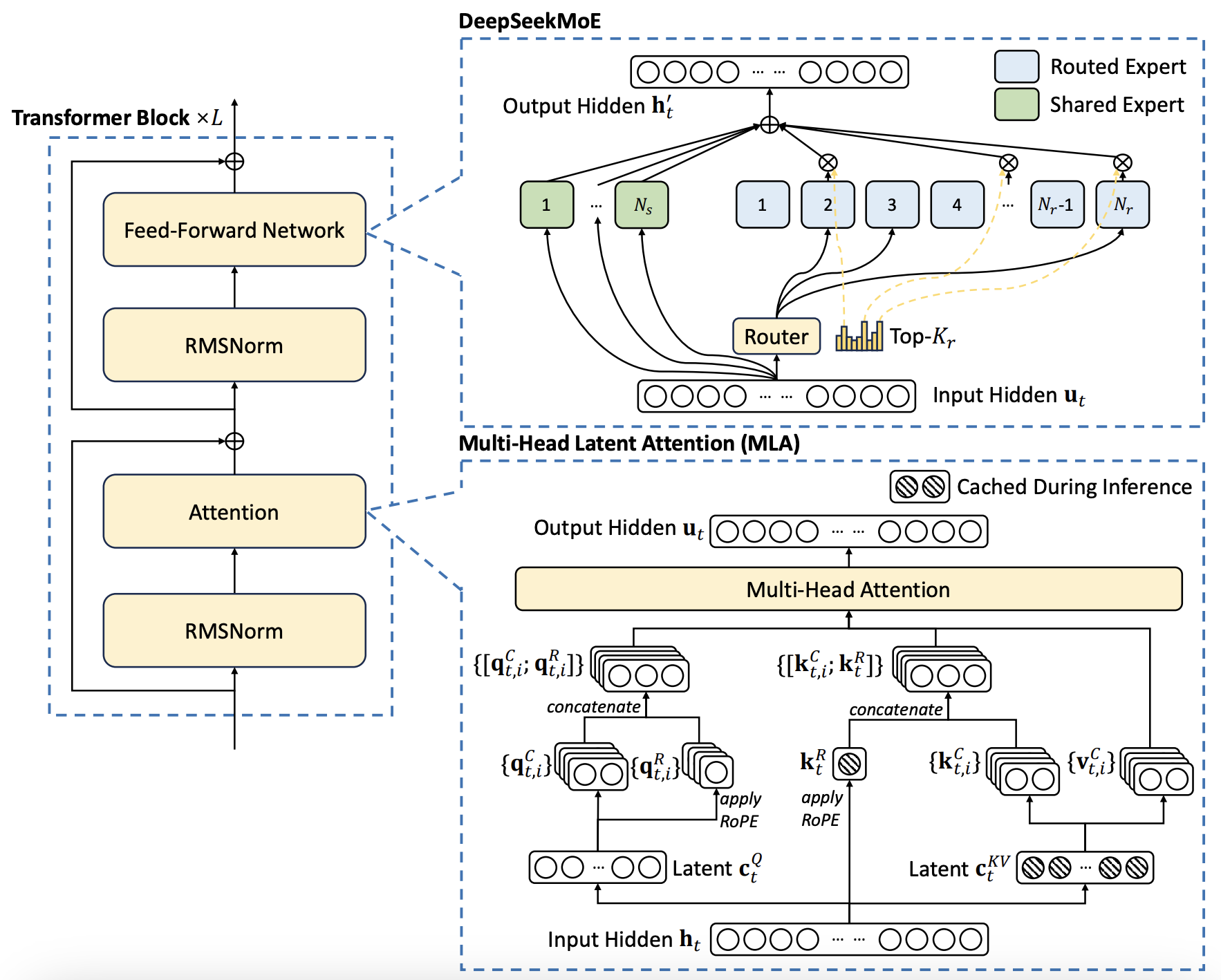 The positive-tuning course of was carried out with a 4096 sequence length on an 8x a100 80GB DGX machine. We additional conduct supervised superb-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, ensuing within the creation of DeepSeek Chat fashions. DeepSeek unveiled its first set of models - DeepSeek Coder, DeepSeek LLM, and DeepSeek Chat - in November 2023. But it surely wasn’t till last spring, when the startup launched its next-gen DeepSeek-V2 household of models, that the AI industry began to take discover. DeepSeek is an artificial intelligence firm that has developed a family of massive language models (LLMs) and AI tools. However, some consultants and analysts in the tech trade remain skeptical about whether the price savings are as dramatic as DeepSeek states, suggesting that the corporate owns 50,000 Nvidia H100 chips that it cannot speak about attributable to US export controls. As a result of effective load balancing technique, DeepSeek-V3 keeps an excellent load balance throughout its full coaching.
The positive-tuning course of was carried out with a 4096 sequence length on an 8x a100 80GB DGX machine. We additional conduct supervised superb-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, ensuing within the creation of DeepSeek Chat fashions. DeepSeek unveiled its first set of models - DeepSeek Coder, DeepSeek LLM, and DeepSeek Chat - in November 2023. But it surely wasn’t till last spring, when the startup launched its next-gen DeepSeek-V2 household of models, that the AI industry began to take discover. DeepSeek is an artificial intelligence firm that has developed a family of massive language models (LLMs) and AI tools. However, some consultants and analysts in the tech trade remain skeptical about whether the price savings are as dramatic as DeepSeek states, suggesting that the corporate owns 50,000 Nvidia H100 chips that it cannot speak about attributable to US export controls. As a result of effective load balancing technique, DeepSeek-V3 keeps an excellent load balance throughout its full coaching.
Moreover, DeepSeek has only described the cost of their final coaching spherical, doubtlessly eliding vital earlier R&D prices. To understand this, first it is advisable to know that AI mannequin costs will be divided into two categories: training costs (a one-time expenditure to create the model) and runtime "inference" prices - the cost of chatting with the mannequin. 5. 5This is the quantity quoted in DeepSeek's paper - I am taking it at face worth, and not doubting this part of it, only the comparison to US company model coaching prices, and the distinction between the associated fee to practice a specific model (which is the $6M) and the overall cost of R&D (which is far greater). Web. Users can join net access at DeepSeek's website. If you are a programmer or researcher who want to access DeepSeek in this manner, please attain out to AI Enablement. Nevertheless, this data appears to be false, as DeepSeek doesn't have access to OpenAI’s internal information and cannot provide dependable insights relating to employee efficiency.
Introducing DeepSeek, OpenAI’s New Competitor: A Full Breakdown of Its Features, Power, and… What's DeepSeek, the Chinese AI startup shaking up tech stocks and spooking buyers? Several nations are involved with DeepSeek’s ties to the Chinese government and potential nationwide safety issues. Liang has said High-Flyer was one of DeepSeek’s investors and supplied a few of its first workers. Any researcher can download and inspect one of these open-source fashions and confirm for themselves that it indeed requires much much less power to run than comparable fashions. DeepSeek has induced fairly a stir in the AI world this week by demonstrating capabilities competitive with - or in some circumstances, better than - the newest fashions from OpenAI, whereas purportedly costing only a fraction of the money and compute power to create. What about energy plants to supply electricity for all of the power-hungry AI data centers? In truth, this mannequin is a strong argument that artificial training data can be used to nice effect in building AI fashions. This value efficiency is achieved by way of less advanced Nvidia H800 chips and revolutionary coaching methodologies that optimize resources with out compromising efficiency. Already, others are replicating the excessive-performance, low-value training approach of DeepSeek. Much has already been fabricated from the apparent plateauing of the "extra data equals smarter fashions" approach to AI advancement.
Should you loved this short article and you want to receive much more information relating to ديب سيك شات kindly visit our webpage.
댓글목록
등록된 댓글이 없습니다.