Excited about Deepseek? Nine Reasons why Its Time To Stop!
페이지 정보
작성자 Kenton 작성일25-02-13 07:35 조회6회 댓글0건관련링크
본문
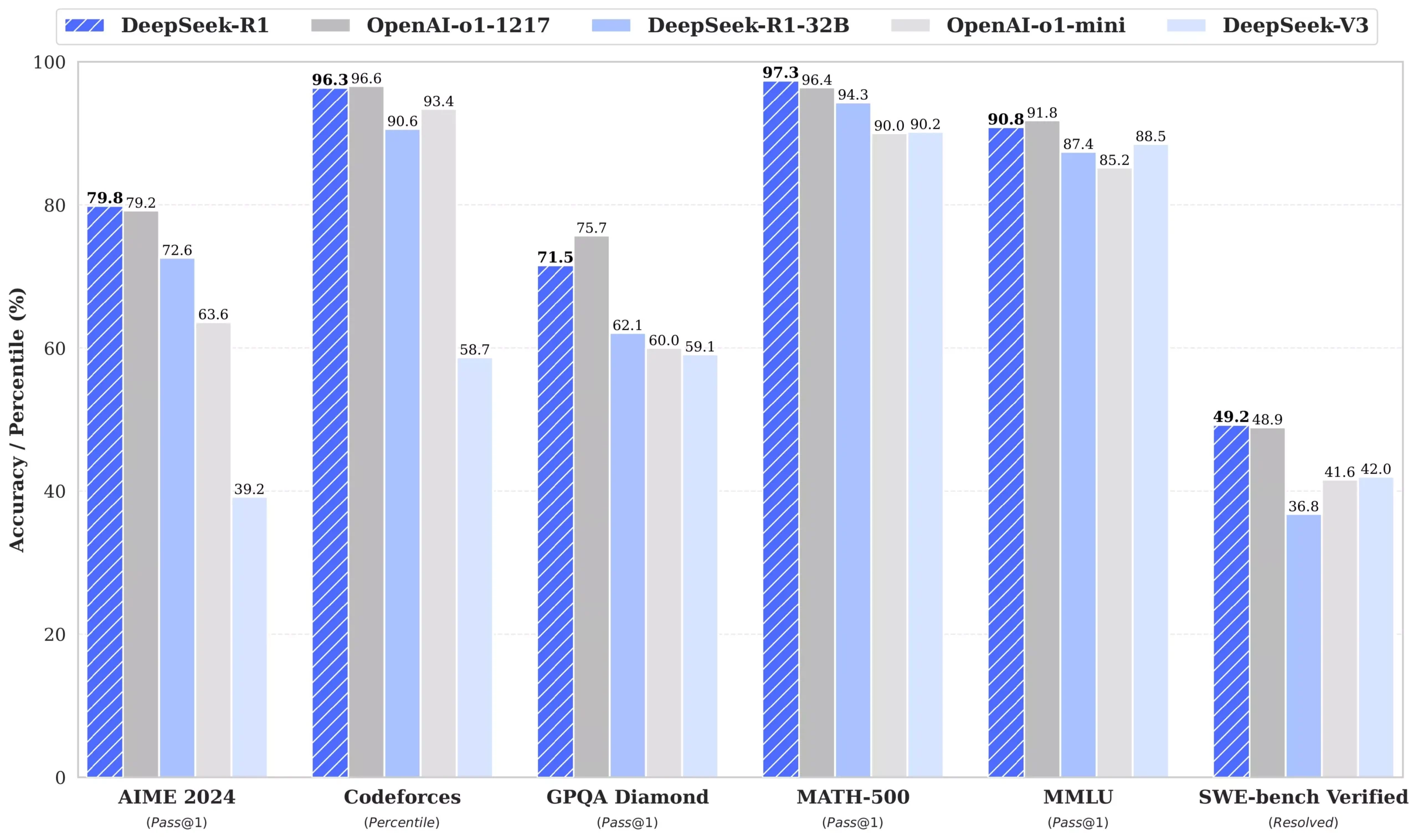 It’s significantly more efficient than different fashions in its class, will get nice scores, and the analysis paper has a bunch of details that tells us that DeepSeek has built a staff that deeply understands the infrastructure required to prepare bold models. I don’t suppose this method works very properly - I tried all the prompts in the paper on Claude 3 Opus and none of them labored, which backs up the concept that the bigger and smarter your model, the more resilient it’ll be. The Hermes 3 collection builds and expands on the Hermes 2 set of capabilities, including more powerful and dependable function calling and structured output capabilities, generalist assistant capabilities, and improved code era abilities. 0.9 per output token compared to GPT-4o's $15. I don't want to bash webpack right here, however I'll say this : webpack is gradual as shit, in comparison with Vite. The Chinese startup DeepSeek has made waves after releasing AI fashions that specialists say match or outperform leading American models at a fraction of the fee. In the second stage, these specialists are distilled into one agent using RL with adaptive KL-regularization.
It’s significantly more efficient than different fashions in its class, will get nice scores, and the analysis paper has a bunch of details that tells us that DeepSeek has built a staff that deeply understands the infrastructure required to prepare bold models. I don’t suppose this method works very properly - I tried all the prompts in the paper on Claude 3 Opus and none of them labored, which backs up the concept that the bigger and smarter your model, the more resilient it’ll be. The Hermes 3 collection builds and expands on the Hermes 2 set of capabilities, including more powerful and dependable function calling and structured output capabilities, generalist assistant capabilities, and improved code era abilities. 0.9 per output token compared to GPT-4o's $15. I don't want to bash webpack right here, however I'll say this : webpack is gradual as shit, in comparison with Vite. The Chinese startup DeepSeek has made waves after releasing AI fashions that specialists say match or outperform leading American models at a fraction of the fee. In the second stage, these specialists are distilled into one agent using RL with adaptive KL-regularization.
 Detailed Analysis: Provide in-depth monetary or technical evaluation using structured data inputs. There are at present no approved non-programmer choices for utilizing non-public data (ie delicate, inner, or extremely sensitive data) with DeepSeek. More countries have since raised concerns over the firm’s data practices. This is a more difficult activity than updating an LLM's knowledge about info encoded in regular text. Large Language Models (LLMs) are a kind of synthetic intelligence (AI) model designed to understand and generate human-like text based mostly on huge quantities of knowledge. Edit the file with a textual content editor. While the paper presents promising results, it is essential to think about the potential limitations and areas for further analysis, resembling generalizability, ethical considerations, computational efficiency, and transparency. These improvements are vital because they've the potential to push the boundaries of what giant language fashions can do in relation to mathematical reasoning and code-associated tasks. We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language mannequin with 671B whole parameters with 37B activated for every token. Full weight fashions (16-bit floats) were served domestically by way of HuggingFace Transformers to judge uncooked mannequin functionality. At first we began evaluating common small code models, but as new models kept appearing we couldn’t resist adding DeepSeek site Coder V2 Light and Mistrals’ Codestral.
Detailed Analysis: Provide in-depth monetary or technical evaluation using structured data inputs. There are at present no approved non-programmer choices for utilizing non-public data (ie delicate, inner, or extremely sensitive data) with DeepSeek. More countries have since raised concerns over the firm’s data practices. This is a more difficult activity than updating an LLM's knowledge about info encoded in regular text. Large Language Models (LLMs) are a kind of synthetic intelligence (AI) model designed to understand and generate human-like text based mostly on huge quantities of knowledge. Edit the file with a textual content editor. While the paper presents promising results, it is essential to think about the potential limitations and areas for further analysis, resembling generalizability, ethical considerations, computational efficiency, and transparency. These improvements are vital because they've the potential to push the boundaries of what giant language fashions can do in relation to mathematical reasoning and code-associated tasks. We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language mannequin with 671B whole parameters with 37B activated for every token. Full weight fashions (16-bit floats) were served domestically by way of HuggingFace Transformers to judge uncooked mannequin functionality. At first we began evaluating common small code models, but as new models kept appearing we couldn’t resist adding DeepSeek site Coder V2 Light and Mistrals’ Codestral.
We additional wonderful-tune the base model with 2B tokens of instruction information to get instruction-tuned models, namedly DeepSeek-Coder-Instruct. In our strategy, we embed a multilingual model (mBART, Liu et al., 2020) into an EC picture-reference sport, wherein the model is incentivized to make use of multilingual generations to accomplish a imaginative and prescient-grounded activity. "Egocentric vision renders the environment partially noticed, amplifying challenges of credit assignment and exploration, requiring the usage of reminiscence and the invention of suitable information seeking methods in order to self-localize, find the ball, avoid the opponent, and rating into the correct objective," they write. On this work, we analyzed two major design selections of S-FFN: the memory block (a.okay.a. Here is how to make use of Mem0 to add a memory layer to Large Language Models. Every new day, we see a brand new Large Language Model. Recently, Firefunction-v2 - an open weights operate calling mannequin has been launched. DeepSeekMath: Pushing the boundaries of Mathematical Reasoning in Open Language and AutoCoder: Enhancing Code with Large Language Models are associated papers that discover similar themes and developments in the field of code intelligence. More information: DeepSeek-V2: A robust, Economical, and Efficient Mixture-of-Experts Language Model (DeepSeek, GitHub).
"Through several iterations, the model trained on massive-scale synthetic knowledge becomes significantly more highly effective than the initially underneath-educated LLMs, resulting in larger-high quality theorem-proof pairs," the researchers write. Here’s another favorite of mine that I now use even more than OpenAI! Remember the third downside concerning the WhatsApp being paid to make use of? In February 2024, Australia banned the use of the corporate's technology on all authorities devices. NOT paid to use. The DeepSeek-Coder-V2 paper introduces a major development in breaking the barrier of closed-supply fashions in code intelligence. The paper presents extensive experimental outcomes, demonstrating the effectiveness of DeepSeek-Prover-V1.5 on a range of challenging mathematical issues. Generalizability: While the experiments reveal robust performance on the tested benchmarks, it's essential to evaluate the model's capacity to generalize to a wider range of programming languages, coding styles, and actual-world situations. My research primarily focuses on pure language processing and code intelligence to allow computers to intelligently course of, perceive and generate each pure language and programming language. On this place paper, we articulate how Emergent Communication (EC) can be used in conjunction with giant pretrained language models as a ‘Fine-Tuning’ (FT) step (therefore, EC-FT) so as to supply them with supervision from such learning situations.
If you liked this informative article and you wish to get guidance about ديب سيك generously stop by the page.
댓글목록
등록된 댓글이 없습니다.