Concern? Not If You utilize Deepseek The fitting Way!
페이지 정보
작성자 Chong 작성일25-02-13 10:53 조회16회 댓글0건관련링크
본문
DeepSeek reduces computing energy consumption by 50% by way of sparse training, and dynamic mannequin pruning enables consumer-grade GPUs to prepare models with tens of billions of parameters. For comparability, high-end GPUs like the Nvidia RTX 3090 boast practically 930 GBps of bandwidth for their VRAM. Trained over 14.Eight trillion various tokens and developed advanced methods like Multi-Token Prediction, DeepSeek v3 units new goals in AI language modeling. Meanwhile, we also maintain a control over the output style and length of DeepSeek-V3. Nvidia alone skilled a staggering decline of over $600 billion. Activated Parameters: DeepSeek V3 has 37 billion activated parameters, whereas DeepSeek V2.5 has 21 billion. While China’s DeepSeek shows you may innovate by way of optimization regardless of limited compute, the US is betting big on raw power - as seen in Altman’s $500 billion Stargate project with Trump. DeepSeek has precipitated fairly a stir within the AI world this week by demonstrating capabilities competitive with - or in some instances, higher than - the latest models from OpenAI, ديب سيك while purportedly costing only a fraction of the money and compute energy to create. All models are evaluated in a configuration that limits the output size to 8K. Benchmarks containing fewer than 1000 samples are examined a number of instances using varying temperature settings to derive sturdy ultimate outcomes.
SGLang additionally helps multi-node tensor parallelism, enabling you to run this mannequin on a number of community-connected machines. LLM: Support DeepSeek-V3 model with FP8 and BF16 modes for tensor parallelism and pipeline parallelism. Also setting it aside from other AI instruments, the DeepThink (R1) mannequin exhibits you its exact "thought course of" and the time it took to get the answer earlier than providing you with a detailed reply. DeepSeek gives two LLMs: DeepSeek-V3 and DeepThink (R1). DeepSeek-V3 works like the standard ChatGPT mannequin, offering fast responses, producing text, rewriting emails and summarizing paperwork. Democrats’ objective "must be a muscular, lean, effective administrative state that works for Americans," she wrote. One beforehand worked in international commerce for German machinery, and the other wrote backend code for a securities firm. We introduce an innovative methodology to distill reasoning capabilities from the long-Chain-of-Thought (CoT) model, specifically from one of the DeepSeek R1 sequence models, into customary LLMs, particularly DeepSeek-V3.
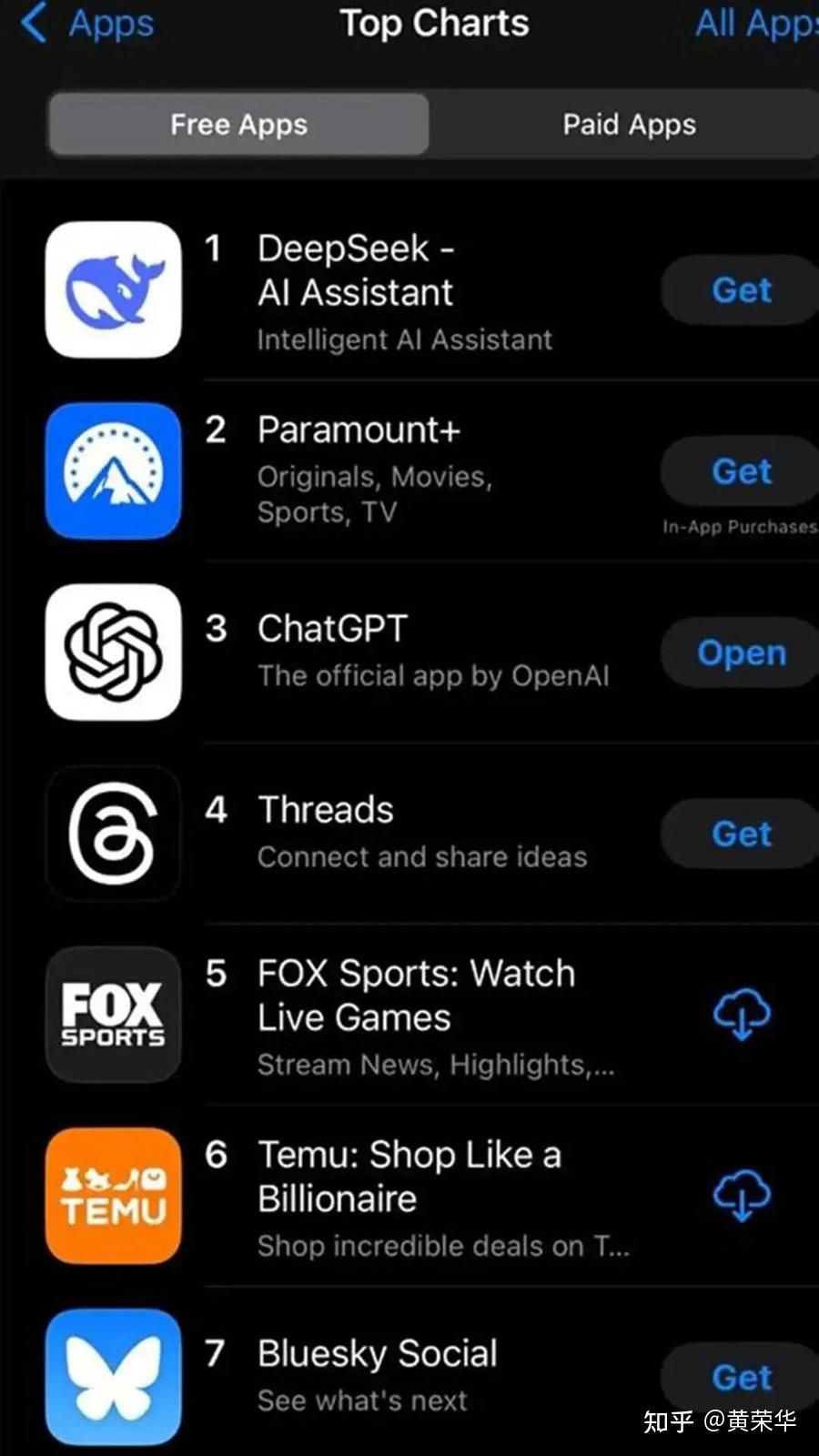 One of the standout options of DeepSeek-R1 is its transparent and competitive pricing mannequin. DeepSeek site-R1 was allegedly created with an estimated budget of $5.5 million, significantly lower than the $one hundred million reportedly spent on OpenAI's GPT-4. Probably the most affect fashions are the language fashions: DeepSeek-R1 is a mannequin similar to ChatGPT's o1, in that it applies self-prompting to offer an look of reasoning. DeepThink (R1) provides another to OpenAI's ChatGPT o1 mannequin, which requires a subscription, but both DeepSeek fashions are free to use. You may ask it a easy question, request help with a challenge, help with research, draft emails and resolve reasoning issues utilizing DeepThink. DeepSeek did not instantly respond to a request for comment about its apparent censorship of certain subjects and individuals. DeepSeek did not immediately respond to a request for remark. The analysis group is granted entry to the open-source variations, DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat.
One of the standout options of DeepSeek-R1 is its transparent and competitive pricing mannequin. DeepSeek site-R1 was allegedly created with an estimated budget of $5.5 million, significantly lower than the $one hundred million reportedly spent on OpenAI's GPT-4. Probably the most affect fashions are the language fashions: DeepSeek-R1 is a mannequin similar to ChatGPT's o1, in that it applies self-prompting to offer an look of reasoning. DeepThink (R1) provides another to OpenAI's ChatGPT o1 mannequin, which requires a subscription, but both DeepSeek fashions are free to use. You may ask it a easy question, request help with a challenge, help with research, draft emails and resolve reasoning issues utilizing DeepThink. DeepSeek did not instantly respond to a request for comment about its apparent censorship of certain subjects and individuals. DeepSeek did not immediately respond to a request for remark. The analysis group is granted entry to the open-source variations, DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat.
 DeepSeek LLM 7B/67B fashions, together with base and chat versions, are released to the public on GitHub, Hugging Face and in addition AWS S3. Trust is essential to AI adoption, and DeepSeek might face pushback in Western markets as a consequence of knowledge privateness, censorship and transparency issues. The issue with DeepSeek's censorship is that it will make jokes about US presidents Joe Biden and Donald Trump, but it surely won't dare so as to add Chinese President Xi Jinping to the combination. US-based mostly AI firms have had their fair share of controversy relating to hallucinations, telling people to eat rocks and rightfully refusing to make racist jokes. If this Mistral playbook is what’s occurring for some of the opposite companies as properly, the perplexity ones. Perplexity has also integrated DeepSeek R1 for higher reasoning capabilities and general smarter responses, which they are working on their servers. Using superior analysis capabilities can benefit varied sectors resembling finance, healthcare, and academia. Recently, Alibaba, the chinese language tech giant also unveiled its own LLM referred to as Qwen-72B, which has been skilled on excessive-quality data consisting of 3T tokens and also an expanded context window size of 32K. Not just that, the company additionally added a smaller language mannequin, Qwen-1.8B, touting it as a gift to the analysis group.
DeepSeek LLM 7B/67B fashions, together with base and chat versions, are released to the public on GitHub, Hugging Face and in addition AWS S3. Trust is essential to AI adoption, and DeepSeek might face pushback in Western markets as a consequence of knowledge privateness, censorship and transparency issues. The issue with DeepSeek's censorship is that it will make jokes about US presidents Joe Biden and Donald Trump, but it surely won't dare so as to add Chinese President Xi Jinping to the combination. US-based mostly AI firms have had their fair share of controversy relating to hallucinations, telling people to eat rocks and rightfully refusing to make racist jokes. If this Mistral playbook is what’s occurring for some of the opposite companies as properly, the perplexity ones. Perplexity has also integrated DeepSeek R1 for higher reasoning capabilities and general smarter responses, which they are working on their servers. Using superior analysis capabilities can benefit varied sectors resembling finance, healthcare, and academia. Recently, Alibaba, the chinese language tech giant also unveiled its own LLM referred to as Qwen-72B, which has been skilled on excessive-quality data consisting of 3T tokens and also an expanded context window size of 32K. Not just that, the company additionally added a smaller language mannequin, Qwen-1.8B, touting it as a gift to the analysis group.
If you liked this information and you would such as to get additional details relating to ديب سيك kindly visit our web page.
댓글목록
등록된 댓글이 없습니다.