Better Call SAL
페이지 정보
작성자 Adrianne 작성일25-02-14 06:31 조회4회 댓글0건관련링크
본문
This leads us to Chinese AI startup DeepSeek. DeepSeek was founded less than two years ago by the Chinese hedge fund High Flyer as a research lab dedicated to pursuing Artificial General Intelligence, or AGI. Similar situations have been observed with other models, like Gemini-Pro, which has claimed to be Baidu's Wenxin when requested in Chinese. Some American AI researchers have cast doubt on DeepSeek’s claims about how a lot it spent, and what number of advanced chips it deployed to create its model. Both DeepSeek and US AI firms have much more cash and plenty of more chips than they used to prepare their headline fashions. Rosie Campbell turns into the latest anxious particular person to go away OpenAI after concluding they'll can’t have sufficient optimistic impression from the inside. At a supposed price of just $6 million to practice, DeepSeek’s new R1 model, launched last week, was in a position to match the efficiency on several math and reasoning metrics by OpenAI’s o1 model - the end result of tens of billions of dollars in investment by OpenAI and its patron Microsoft. Now, rapidly, it’s like, "Oh, OpenAI has a hundred million customers, and we need to construct Bard and Gemini to compete with them." That’s a totally completely different ballpark to be in.
 And it’s simply the latest headwind for the group. T. Rowe Price Science and Technology equity technique portfolio manager Tony Wang advised me he sees the group as "well positioned," whereas Stifel’s Ruben Roy additionally sees upside, citing DeepSeek’s R1 mannequin as a driver of worldwide demand for robust and excessive-pace networking infrastructure. Being enthusiastic about progress in science is one thing that we should all want, and seeing the price of a essential useful resource come down is also something we should always need," explained Zack Kass, OpenAI’s former head of Go-To-Market. The Facebook/React team don't have any intention at this point of fixing any dependency, as made clear by the fact that create-react-app is now not up to date and so they now suggest other tools (see additional down). Updated on 1st February - You should use the Bedrock playground for understanding how the mannequin responds to numerous inputs and letting you positive-tune your prompts for optimal results. Cloud customers will see these default models appear when their instance is up to date. The Guardian. Cite error: The named reference "vincent" was defined a number of times with completely different content (see the help web page). See my checklist of GPT achievements.
And it’s simply the latest headwind for the group. T. Rowe Price Science and Technology equity technique portfolio manager Tony Wang advised me he sees the group as "well positioned," whereas Stifel’s Ruben Roy additionally sees upside, citing DeepSeek’s R1 mannequin as a driver of worldwide demand for robust and excessive-pace networking infrastructure. Being enthusiastic about progress in science is one thing that we should all want, and seeing the price of a essential useful resource come down is also something we should always need," explained Zack Kass, OpenAI’s former head of Go-To-Market. The Facebook/React team don't have any intention at this point of fixing any dependency, as made clear by the fact that create-react-app is now not up to date and so they now suggest other tools (see additional down). Updated on 1st February - You should use the Bedrock playground for understanding how the mannequin responds to numerous inputs and letting you positive-tune your prompts for optimal results. Cloud customers will see these default models appear when their instance is up to date. The Guardian. Cite error: The named reference "vincent" was defined a number of times with completely different content (see the help web page). See my checklist of GPT achievements.
After checking out the model element page including the model’s capabilities, and implementation tips, you can directly deploy the model by offering an endpoint title, selecting the variety of cases, and choosing an occasion kind. The outcomes turned out to be higher than the optimized kernels developed by skilled engineers in some cases. The experiment was to routinely generate GPU attention kernels that were numerically right and optimized for various flavors of consideration with none express programming. The level-1 solving price in KernelBench refers back to the numerical right metric used to evaluate the ability of LLMs to generate efficient GPU kernels for particular computational tasks. To date, China appears to have struck a useful balance between content material control and quality of output, impressing us with its skill to take care of prime quality within the face of restrictions. Not to say Apple also makes the very best cell chips, so could have a decisive benefit running local models too. It appears to be like incredible, and I will check it for certain. Experts say the sluggish economy, high unemployment and Covid lockdowns have all performed a role on this sentiment, while the Communist Party's tightening grip has also shrunk shops for individuals to vent their frustrations.
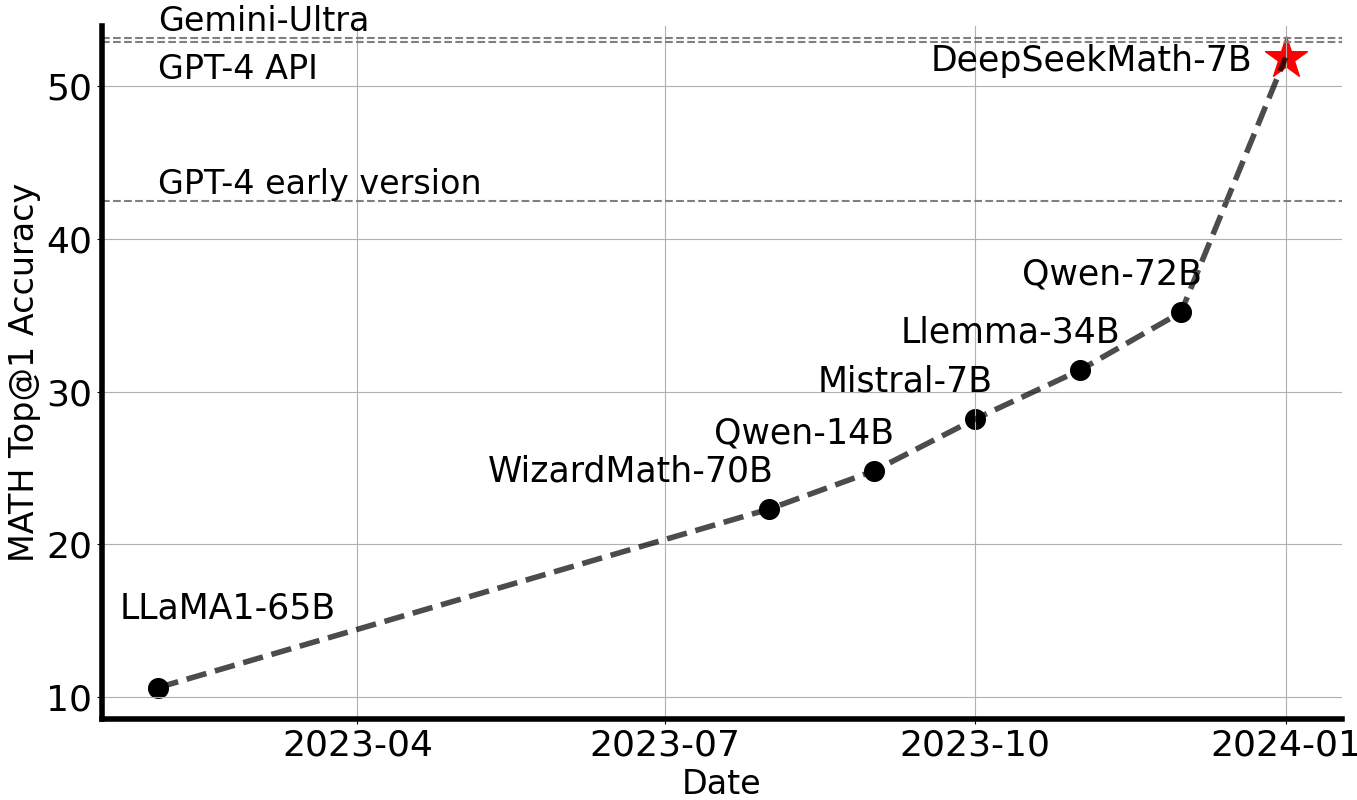
 ChatGPT is a time period most individuals are accustomed to. As the field of giant language models for mathematical reasoning continues to evolve, the insights and strategies presented in this paper are likely to inspire additional developments and contribute to the development of much more capable and versatile mathematical AI programs. The researchers have developed a new AI system called DeepSeek-Coder-V2 that aims to beat the limitations of existing closed-supply fashions in the field of code intelligence. Do you employ or have built some other cool tool or framework? Yep, AI editing the code to use arbitrarily giant sources, certain, why not. The paper presents a new large language mannequin referred to as DeepSeekMath 7B that's particularly designed to excel at mathematical reasoning. Smoothquant: Accurate and environment friendly publish-coaching quantization for giant language models. At the large scale, we prepare a baseline MoE mannequin comprising roughly 230B total parameters on around 0.9T tokens. We validate our FP8 mixed precision framework with a comparison to BF16 coaching on prime of two baseline fashions throughout different scales. A well-liked method for avoiding routing collapse is to power "balanced routing", i.e. the property that every professional is activated roughly an equal number of occasions over a sufficiently massive batch, by adding to the coaching loss a term measuring how imbalanced the skilled routing was in a specific batch.
ChatGPT is a time period most individuals are accustomed to. As the field of giant language models for mathematical reasoning continues to evolve, the insights and strategies presented in this paper are likely to inspire additional developments and contribute to the development of much more capable and versatile mathematical AI programs. The researchers have developed a new AI system called DeepSeek-Coder-V2 that aims to beat the limitations of existing closed-supply fashions in the field of code intelligence. Do you employ or have built some other cool tool or framework? Yep, AI editing the code to use arbitrarily giant sources, certain, why not. The paper presents a new large language mannequin referred to as DeepSeekMath 7B that's particularly designed to excel at mathematical reasoning. Smoothquant: Accurate and environment friendly publish-coaching quantization for giant language models. At the large scale, we prepare a baseline MoE mannequin comprising roughly 230B total parameters on around 0.9T tokens. We validate our FP8 mixed precision framework with a comparison to BF16 coaching on prime of two baseline fashions throughout different scales. A well-liked method for avoiding routing collapse is to power "balanced routing", i.e. the property that every professional is activated roughly an equal number of occasions over a sufficiently massive batch, by adding to the coaching loss a term measuring how imbalanced the skilled routing was in a specific batch.
댓글목록
등록된 댓글이 없습니다.