The Number one Question It's Essential to Ask For Deepseek
페이지 정보
작성자 Rochelle 작성일25-02-14 18:53 조회6회 댓글0건관련링크
본문
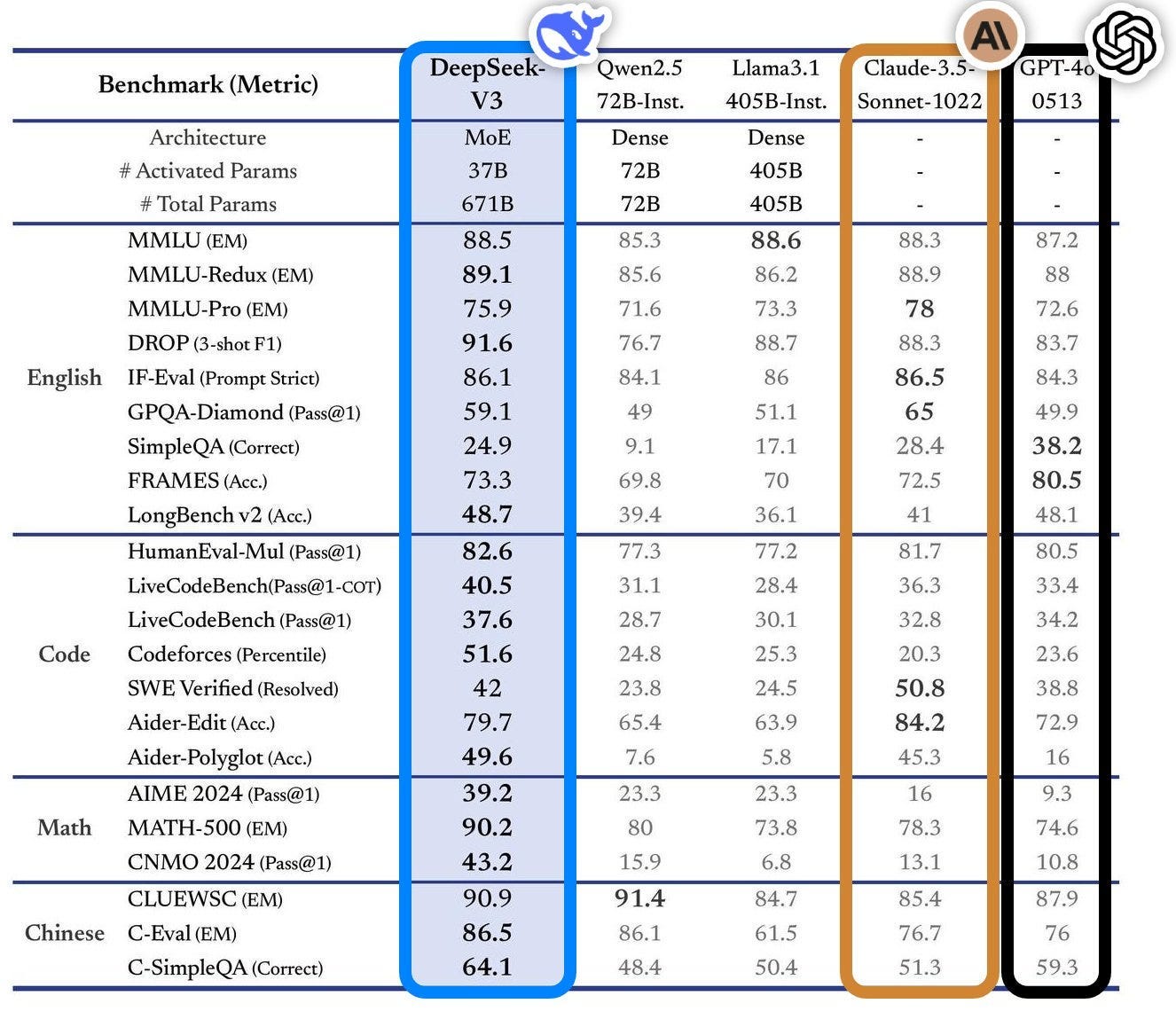
 From the DeepSeek v3 technical report. Led by CEO Liang Wenfeng, the 2-year-outdated DeepSeek is China’s premier AI startup. Founded in 2023 by a hedge fund supervisor, Liang Wenfeng, the company is headquartered in Hangzhou, China, and makes a speciality of growing open-source giant language models. It spun out from a hedge fund founded by engineers from Zhejiang University and is concentrated on "potentially game-changing architectural and algorithmic innovations" to build synthetic basic intelligence (AGI) - or at the least, that’s what Liang says. DeepSeek, the beginning-up in Hangzhou that constructed the model, has released it as ‘open-weight’, which means that researchers can examine and construct on the algorithm. There are nonetheless a number of unknown variables as they relate to precise dollar figures and the coaching methodologies that DeepSeek used to build its model, known as R1. "Most people, when they are younger, can devote themselves completely to a mission without utilitarian issues," he defined. It will probably stop a specific software that’s not responding, stop all functions directly, empty the trash, power logout, restart the mac, sleep displays, send pc to sleep, control the apple music utility from shortcuts and key phrases. The AP took Feroot’s findings to a second set of pc consultants, who independently confirmed that China Mobile code is present.
From the DeepSeek v3 technical report. Led by CEO Liang Wenfeng, the 2-year-outdated DeepSeek is China’s premier AI startup. Founded in 2023 by a hedge fund supervisor, Liang Wenfeng, the company is headquartered in Hangzhou, China, and makes a speciality of growing open-source giant language models. It spun out from a hedge fund founded by engineers from Zhejiang University and is concentrated on "potentially game-changing architectural and algorithmic innovations" to build synthetic basic intelligence (AGI) - or at the least, that’s what Liang says. DeepSeek, the beginning-up in Hangzhou that constructed the model, has released it as ‘open-weight’, which means that researchers can examine and construct on the algorithm. There are nonetheless a number of unknown variables as they relate to precise dollar figures and the coaching methodologies that DeepSeek used to build its model, known as R1. "Most people, when they are younger, can devote themselves completely to a mission without utilitarian issues," he defined. It will probably stop a specific software that’s not responding, stop all functions directly, empty the trash, power logout, restart the mac, sleep displays, send pc to sleep, control the apple music utility from shortcuts and key phrases. The AP took Feroot’s findings to a second set of pc consultants, who independently confirmed that China Mobile code is present.
 Part of the buzz round DeepSeek is that it has succeeded in making R1 despite US export controls that restrict Chinese firms’ entry to one of the best pc chips designed for AI processing. Spun off a hedge fund, DeepSeek emerged from relative obscurity last month when it launched a chatbot known as V3, which outperformed major rivals, despite being built on a shoestring funds. DeepSeek’s two AI models, launched in quick succession, put it on par with the most effective accessible from American labs, according to Alexandr Wang, Scale AI CEO. In solely two months, DeepSeek got here up with something new and interesting. Today, DeepSeek is one among the only leading AI firms in China that doesn’t rely on funding from tech giants like Baidu, Alibaba, or ByteDance. In October 2022, the US government started putting together export controls that severely restricted Chinese AI corporations from accessing reducing-edge chips like Nvidia’s H100. The news might spell trouble for the present US export controls that focus on creating computing resource bottlenecks. Gary Marcus, a professor emeritus of psychology and neuroscience at New York University, who focuses on AI, advised ABC News.
Part of the buzz round DeepSeek is that it has succeeded in making R1 despite US export controls that restrict Chinese firms’ entry to one of the best pc chips designed for AI processing. Spun off a hedge fund, DeepSeek emerged from relative obscurity last month when it launched a chatbot known as V3, which outperformed major rivals, despite being built on a shoestring funds. DeepSeek’s two AI models, launched in quick succession, put it on par with the most effective accessible from American labs, according to Alexandr Wang, Scale AI CEO. In solely two months, DeepSeek got here up with something new and interesting. Today, DeepSeek is one among the only leading AI firms in China that doesn’t rely on funding from tech giants like Baidu, Alibaba, or ByteDance. In October 2022, the US government started putting together export controls that severely restricted Chinese AI corporations from accessing reducing-edge chips like Nvidia’s H100. The news might spell trouble for the present US export controls that focus on creating computing resource bottlenecks. Gary Marcus, a professor emeritus of psychology and neuroscience at New York University, who focuses on AI, advised ABC News.
"Unlike many Chinese AI companies that rely closely on access to advanced hardware, DeepSeek has targeted on maximizing software-driven useful resource optimization," explains Marina Zhang, an associate professor on the University of Technology Sydney, who studies Chinese innovations. The firm had began out with a stockpile of 10,000 A100’s, however it wanted extra to compete with companies like OpenAI and Meta. While it responds to a prompt, use a command like btop to check if the GPU is getting used successfully. A second level to consider is why DeepSeek is coaching on only 2048 GPUs while Meta highlights training their model on a better than 16K GPU cluster. DeepSeek-V3 is educated on a cluster geared up with 2048 NVIDIA H800 GPUs. For years, High-Flyer had been stockpiling GPUs and constructing Fire-Flyer supercomputers to investigate monetary information. Published below an MIT licence, the model might be freely reused but shouldn't be thought of totally open source, as a result of its coaching information haven't been made out there.
The large tech firms are the only ones which have the money and the sources and the info centers and all that information infrastructure to do these items, and that is one thing that is different than earlier than. What the agents are fabricated from: Nowadays, greater than half of the stuff I write about in Import AI includes a Transformer architecture model (developed 2017). Not here! These agents use residual networks which feed into an LSTM (for reminiscence) and then have some totally linked layers and an actor loss and MLE loss. This compression allows for extra efficient use of computing sources, making the model not only powerful but additionally extremely economical when it comes to useful resource consumption. In fact, DeepSeek's newest mannequin is so environment friendly that it required one-tenth the computing power of Meta's comparable Llama 3.1 model to prepare, according to the analysis institution Epoch AI. It was as if Jane Street had decided to grow to be an AI startup and burn its cash on scientific analysis. "My solely hope is that the eye given to this announcement will foster higher intellectual curiosity in the topic, additional develop the talent pool, and, final however not least, improve each personal and public funding in AI research in the US," Javidi told Al Jazeera.
댓글목록
등록된 댓글이 없습니다.