The most typical Deepseek Debate Is not As simple as You Might imagine
페이지 정보
작성자 Rich 작성일25-02-16 12:47 조회9회 댓글0건관련링크
본문
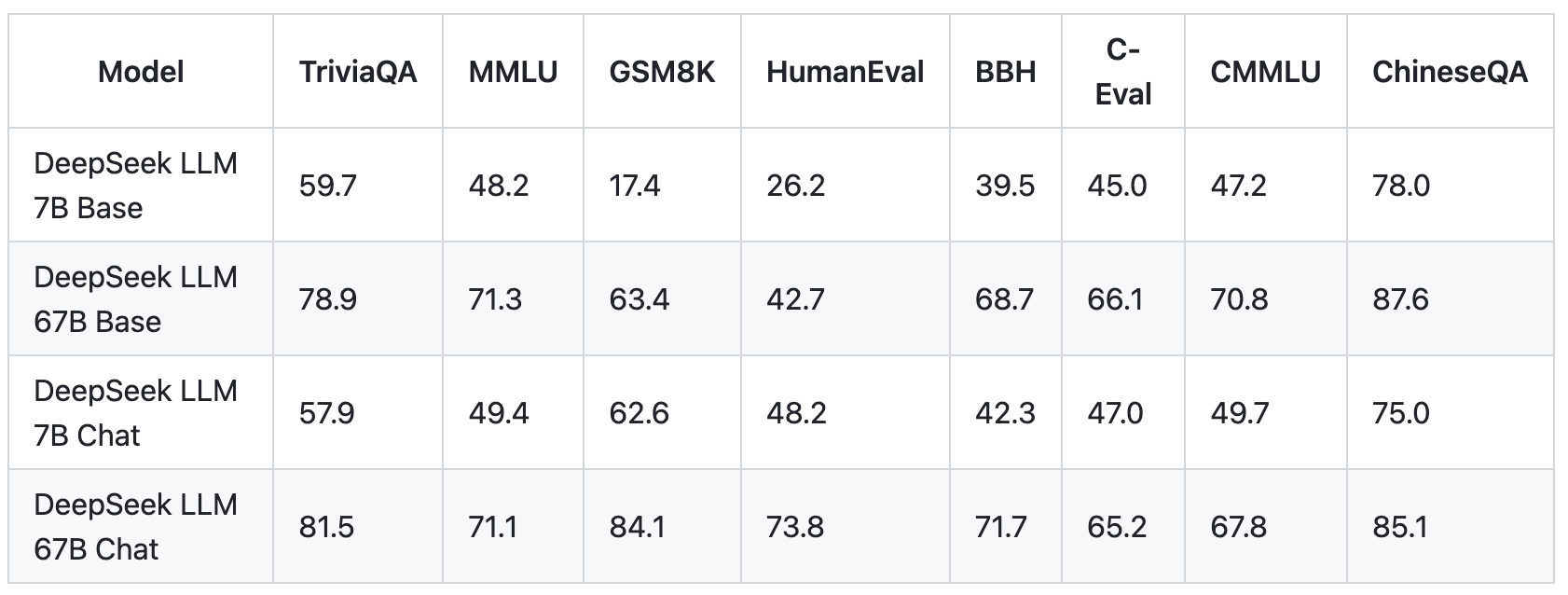
DeepSeek used artificial knowledge to wonderful-tune the mannequin. A possible rationalization is that MATH-500 contains data within R1’s training distribution, whereas U-MATH contains out-of-domain challenges. However, the performance hole turns into extra noticeable in area of interest and out-of-domain areas. Why does o1 perform better in these specialised areas? Is DeepSeek R1 actually sturdy in arithmetic? While R1 outperforms o1 on MATH-500, it struggles with more advanced college-degree issues. By offering entry to its robust capabilities, DeepSeek-V3 can drive innovation and improvement in areas such as software engineering and algorithm growth, empowering builders and researchers to push the boundaries of what open-supply fashions can obtain in coding duties. Its strong algorithm and tools guarantee users with data evaluation and job automation abilities. Using a small LLM-generated and human-curated dataset of demonstrations, the model was first educated on excessive-high quality reasoning knowledge (math and code). Toloka’s researchers have conducted additional tests on U-MATH, a dataset of complicated university-stage arithmetic, where R1 carried out significantly worse than o1. I’ve performed round a good amount with them and have come away just impressed with the performance. Assuming the rental value of the H800 GPU is $2 per GPU hour, our complete training costs amount to only $5.576M.
 Under this configuration, DeepSeek-V3 comprises 671B complete parameters, of which 37B are activated for every token. DeepSeek and OpenAI’s o3-mini are two main AI fashions, each with distinct improvement philosophies, cost constructions, and accessibility features. Users can discover loopholes to insert dangerous and false information into this AI, resulting in misuse of this software for unethical purposes. Thus, let's learn about its makes use of in the following circumstances and study how one can put it to use on your purpose. It’s designed to align with human preferences and has been optimized for varied tasks, together with writing and instruction following. The next are a few of the challenges this AI faces that may influence its long-term success. You can integrate these from the DeepSeek software program and undergo their detailed guides to ensure a seamless workflow. It might analyze information, prioritize tasks, and extract useful insights from paperwork to make sure a structured workflow. IoT units geared up with DeepSeek’s AI capabilities can monitor traffic patterns, handle vitality consumption, and even predict upkeep wants for public infrastructure. Users can easily free obtain DeepSeek on their Android and iPhone devices from their respective stores. It can be easily accessed on-line and in your cell devices Free DeepSeek v3 of charge, and you'll utilize the superior DeepThink (R1) mode for improved search outcomes.
Under this configuration, DeepSeek-V3 comprises 671B complete parameters, of which 37B are activated for every token. DeepSeek and OpenAI’s o3-mini are two main AI fashions, each with distinct improvement philosophies, cost constructions, and accessibility features. Users can discover loopholes to insert dangerous and false information into this AI, resulting in misuse of this software for unethical purposes. Thus, let's learn about its makes use of in the following circumstances and study how one can put it to use on your purpose. It’s designed to align with human preferences and has been optimized for varied tasks, together with writing and instruction following. The next are a few of the challenges this AI faces that may influence its long-term success. You can integrate these from the DeepSeek software program and undergo their detailed guides to ensure a seamless workflow. It might analyze information, prioritize tasks, and extract useful insights from paperwork to make sure a structured workflow. IoT units geared up with DeepSeek’s AI capabilities can monitor traffic patterns, handle vitality consumption, and even predict upkeep wants for public infrastructure. Users can easily free obtain DeepSeek on their Android and iPhone devices from their respective stores. It can be easily accessed on-line and in your cell devices Free DeepSeek v3 of charge, and you'll utilize the superior DeepThink (R1) mode for improved search outcomes.
Optimized Resource Constraints: DeepSeek can be improved through the use of environment friendly algorithms and model optimization. Optimized Marketing Content: For advertising campaigns, customers can make the most of DeepSeek AI to generate optimized content material and counsel hashtags, headlines, media posts, and extra. The final outcomes have been optimized for helpfulness, while each reasoning chains and results have been tuned for security. Additionally, embrace basic SFT information for non-auto-verifiable duties and human preferences for final model alignment. Instead of effective-tuning first, they utilized RL with math and coding duties early in coaching to reinforce reasoning talents. The model’s expertise were then refined and expanded beyond the math and coding domains by means of tremendous-tuning for non-reasoning tasks. Traditionally, large models undergo supervised positive-tuning (SFT) first, followed by reinforcement studying (RL) for alignment and tuning on complicated duties. It barely outperforms o1 in reasoning tasks (e.g., Math 500, SWE Verified) and falls just behind usually data benchmarks (MMLU, Simple QA). DeepSeek Coder V2 represents a significant leap ahead in the realm of AI-powered coding and mathematical reasoning. Models like Deepseek Coder V2 and Llama three 8b excelled in dealing with superior programming concepts like generics, greater-order features, and data buildings.
I feel the ROI on getting LLaMA was most likely much greater, particularly by way of brand. The increasingly more jailbreak analysis I learn, the more I think it’s principally going to be a cat and mouse recreation between smarter hacks and fashions getting sensible sufficient to know they’re being hacked - and proper now, for any such hack, the models have the advantage. So I do not assume it is that. And even top-of-the-line fashions at present out there, gpt-4o nonetheless has a 10% likelihood of producing non-compiling code. Rather a lot can go fallacious even for such a easy instance. Therefore, any form of bias in the information can result in inaccurate info and responses, impacting consumer's trust. But concerns about information privateness and ethical AI usage persist. Data Privacy: Users have reported safety concerns about this AI platform, referring to the danger of information leaks and unauthorized access. To replicate or exceed their success, prioritize excessive-high quality knowledge for this stage. This stage provided the largest performance boost. The most significant efficiency enhance in DeepSeek R1 got here from reasoning-oriented RL.
댓글목록
등록된 댓글이 없습니다.