This Organization could Be Called DeepSeek
페이지 정보
작성자 Glen 작성일25-02-17 11:57 조회9회 댓글0건관련링크
본문
 These are a set of personal notes concerning the deepseek core readings (prolonged) (elab). The models are too inefficient and too prone to hallucinations. Find the settings for DeepSeek beneath Language Models. DeepSeek is an advanced open-source Large Language Model (LLM). Hence, proper now, this mannequin has its variations of DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat open supply for the research neighborhood. A normal Google search, OpenAI and Gemini all failed to give me anyplace close to the suitable answer. If you would like any custom settings, set them after which click on Save settings for this model followed by Reload the Model in the top right. Feng, Rebecca. "Top Chinese Quant Fund Apologizes to Investors After Recent Struggles". Chinese AI startup DeepSeek AI has ushered in a brand new era in massive language fashions (LLMs) by debuting the DeepSeek LLM household. LobeChat is an open-supply large language model dialog platform dedicated to making a refined interface and excellent user expertise, supporting seamless integration with DeepSeek fashions. Choose a DeepSeek model to your assistant to start the conversation. In 2016, High-Flyer experimented with a multi-issue worth-quantity based mostly model to take inventory positions, began testing in trading the next yr after which extra broadly adopted machine learning-based mostly methods.
These are a set of personal notes concerning the deepseek core readings (prolonged) (elab). The models are too inefficient and too prone to hallucinations. Find the settings for DeepSeek beneath Language Models. DeepSeek is an advanced open-source Large Language Model (LLM). Hence, proper now, this mannequin has its variations of DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat open supply for the research neighborhood. A normal Google search, OpenAI and Gemini all failed to give me anyplace close to the suitable answer. If you would like any custom settings, set them after which click on Save settings for this model followed by Reload the Model in the top right. Feng, Rebecca. "Top Chinese Quant Fund Apologizes to Investors After Recent Struggles". Chinese AI startup DeepSeek AI has ushered in a brand new era in massive language fashions (LLMs) by debuting the DeepSeek LLM household. LobeChat is an open-supply large language model dialog platform dedicated to making a refined interface and excellent user expertise, supporting seamless integration with DeepSeek fashions. Choose a DeepSeek model to your assistant to start the conversation. In 2016, High-Flyer experimented with a multi-issue worth-quantity based mostly model to take inventory positions, began testing in trading the next yr after which extra broadly adopted machine learning-based mostly methods.
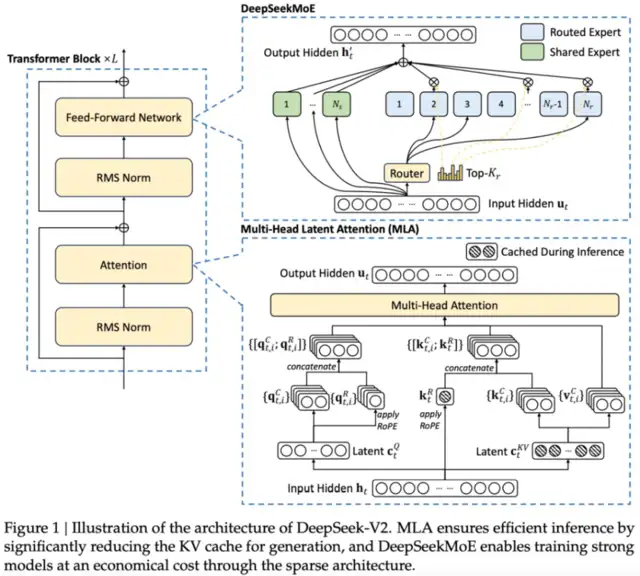
She is a highly enthusiastic individual with a eager curiosity in Machine studying, Data science and AI and an avid reader of the latest developments in these fields. Register with LobeChat now, integrate with DeepSeek API, and expertise the latest achievements in synthetic intelligence expertise. The newest model, DeepSeek-V2, has undergone vital optimizations in structure and performance, with a 42.5% discount in coaching costs and a 93.3% discount in inference prices. This not only improves computational effectivity but also considerably reduces training prices and inference time. Multi-Head Latent Attention (MLA): This novel consideration mechanism reduces the bottleneck of key-value caches throughout inference, enhancing the model's potential to handle long contexts. For suggestions on the best computer hardware configurations to handle Deepseek models smoothly, check out this guide: Best Computer for Running LLaMA and LLama-2 Models. ChatGPT requires an web connection, but DeepSeek V3 can work offline should you install it in your computer. If the website I go to does not work with Librewolf I take advantage of the default Safari browser. I’ve tried utilizing the Tor Browser for elevated security, but sadly most web sites on the clear web will block it routinely which makes it unusable as a every day-use browser. Securely retailer the important thing as it should only appear as soon as.
 If lost, you will need to create a brand new key. During utilization, chances are you'll need to pay the API service supplier, discuss with DeepSeek's relevant pricing policies. To fully leverage the highly effective options of DeepSeek, it is strongly recommended for customers to utilize DeepSeek's API via the LobeChat platform. Coming from China, DeepSeek's technical improvements are turning heads in Silicon Valley. These improvements spotlight China's growing position in AI, challenging the notion that it solely imitates somewhat than innovates, and signaling its ascent to world AI leadership. One of the standout features of DeepSeek’s LLMs is the 67B Base version’s exceptional performance compared to the Llama2 70B Base, showcasing superior capabilities in reasoning, coding, arithmetic, and Chinese comprehension. Comprising the DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat - these open-supply fashions mark a notable stride forward in language comprehension and versatile software. Lean is a purposeful programming language and interactive theorem prover designed to formalize mathematical proofs and verify their correctness. To resolve this drawback, the researchers propose a way for generating intensive Lean 4 proof information from informal mathematical issues. The researchers evaluated their model on the Lean 4 miniF2F and FIMO benchmarks, which include a whole bunch of mathematical issues.
If lost, you will need to create a brand new key. During utilization, chances are you'll need to pay the API service supplier, discuss with DeepSeek's relevant pricing policies. To fully leverage the highly effective options of DeepSeek, it is strongly recommended for customers to utilize DeepSeek's API via the LobeChat platform. Coming from China, DeepSeek's technical improvements are turning heads in Silicon Valley. These improvements spotlight China's growing position in AI, challenging the notion that it solely imitates somewhat than innovates, and signaling its ascent to world AI leadership. One of the standout features of DeepSeek’s LLMs is the 67B Base version’s exceptional performance compared to the Llama2 70B Base, showcasing superior capabilities in reasoning, coding, arithmetic, and Chinese comprehension. Comprising the DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat - these open-supply fashions mark a notable stride forward in language comprehension and versatile software. Lean is a purposeful programming language and interactive theorem prover designed to formalize mathematical proofs and verify their correctness. To resolve this drawback, the researchers propose a way for generating intensive Lean 4 proof information from informal mathematical issues. The researchers evaluated their model on the Lean 4 miniF2F and FIMO benchmarks, which include a whole bunch of mathematical issues.
Mathematics and Reasoning: DeepSeek demonstrates strong capabilities in solving mathematical problems and reasoning duties. This led the Free DeepSeek AI crew to innovate further and develop their very own approaches to solve these current problems. Their revolutionary approaches to attention mechanisms and the Mixture-of-Experts (MoE) technique have led to spectacular efficiency features. While much consideration in the AI group has been targeted on fashions like LLaMA and Mistral, DeepSeek has emerged as a significant participant that deserves nearer examination. Another surprising thing is that DeepSeek small fashions usually outperform varied greater models. At first we started evaluating popular small code models, but as new fashions saved showing we couldn’t resist adding DeepSeek Coder V2 Light and Mistrals’ Codestral. Initially, DeepSeek created their first mannequin with architecture just like different open models like LLaMA, aiming to outperform benchmarks. Consequently, we made the choice to not incorporate MC data within the pre-training or high-quality-tuning process, as it might lead to overfitting on benchmarks.
댓글목록
등록된 댓글이 없습니다.